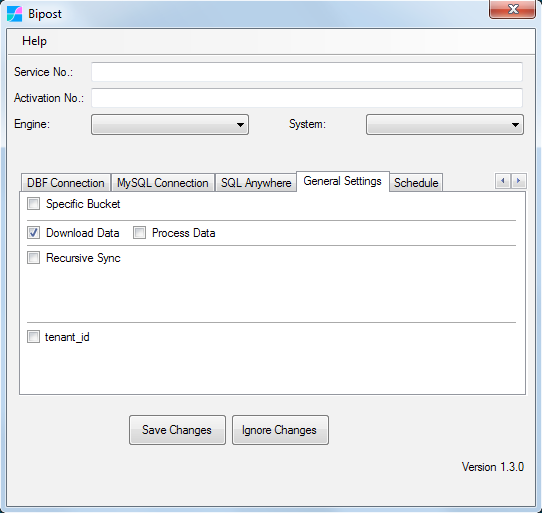
Download Data to On-Prem¶
In some cases Aurora-MySQL is used to make transactions with web applications. In this case it is useful to download data sets from Aurora-MySQL to on-premises.
-
With this option you are able to download data from Aurora to on-premises Windows.
-
Data to retrieve from Aurora is specified on outData.json
-
Process Data is used to update/insert returned data to SQL Server or Firebird SQL. This option is not supported for DBF files.
outData.json¶
-
With this file you are able to specify tables, fields and filter criteria to extract data from Aurora.
-
MySQL tables are case-sensitive, so this is important on
"table":parameter. -
Downloaded data will be available on
%localappdata%/biPost/out_Windows folder. -
recursiveDateFieldparameter not supported.
We highly recommend to prepare your data set on separate non-transactional tables, and process them with Bipost API Final Statement.
Example 1, using outData.json
{
"out": [
{
"active": "true",
"table": "export_doctos_ve",
"fields": "*",
"filter": "",
"recursiveDateField": ""
},
{
"active": "true",
"table": "export_doctos_ve_det",
"fields": "*",
"filter": "",
"recursiveDateField": ""
},
{
"active": "true",
"table": "export_doctos_cm",
"fields": "*",
"filter": "",
"recursiveDateField": ""
},
{
"active": "true",
"table": "export_doctos_cm_det",
"fields": "*",
"filter": "",
"recursiveDateField": ""
}
],
"initialQuery": "",
"finalQuery": ""
}
Example 2, using outData.json
{
"out": [
{
"active": "true",
"table": "biArticulos",
"fields": "*",
"filter": "linea = 'TVs'",
"recursiveDateField": ""
},
{
"active": "",
"table": "",
"fields": "",
"filter": "",
"recursiveDateField": ""
}
],
"initialQuery": "",
"finalQuery": ""
}
Note that you can leave
"active": "",empty.
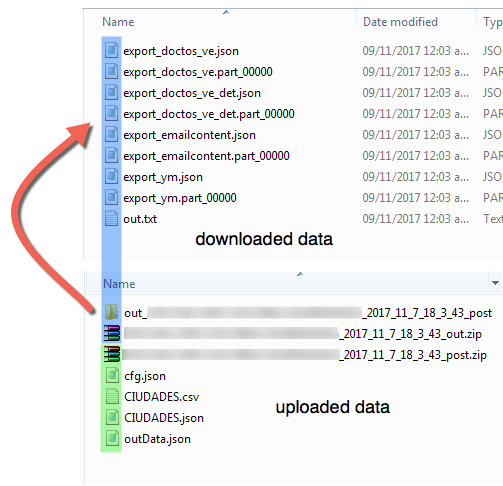
Example of downloaded data on %localappdata%/bipost folder:
Process Data¶
-
When this option is on, table schema's are created/altered and data uploaded to your SQL Server or Firebird SQL.
-
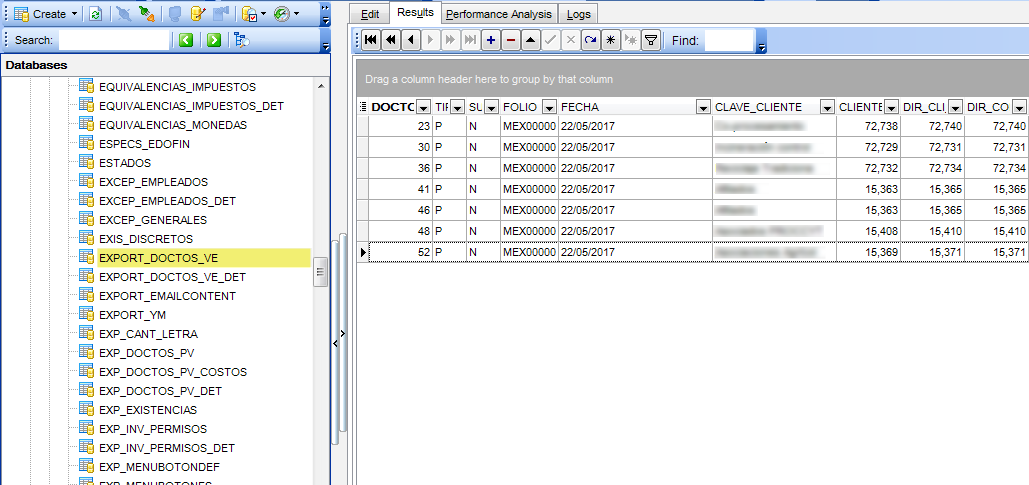
Same names of output tables on Aurora are created on SQL Server/Firebird.
-
We highly recommend to create specific output tables on Aurora and give them a name that is not in use on your SQL Server/Firebird database.
-
Primary keys on Aurora are used on SQL Server/Firebird to avoid duplicates.
-
You are able to query views from Aurora as output. In this case tables on SQL Server/Firebird are always deleted before any new data load.
-
Schema changes on Aurora are applied to SQL Server/Firebird, except for deleting and renaming columns.
-
Run queries before and after data is loaded to SQL Server/Firebird, more instructions below.
-
Firebird SQL does not naturally support creating a column name starting with underscore, so avoid that on Aurora if your on-prem DB is Firebird.
Example of processed data: tables were created and data loaded.
Initial and Final Query¶
Before and after data is loaded to SQL Server/Firebird you're able to run queries, example:
{
"out": [
{
"active": "true",
"table": "biArticulos",
"fields": "*",
"filter": "linea = 'TVs'",
"recursiveDateField": ""
}
],
"initialQuery": "execute procedure spInitial;",
"finalQuery": "execute procedure spFinal;"
}
initialQuery and finalQuery are used to transform your data in any way you want.